OpenAI 遭实锤:研究称其 AI 模型“记住”了受版权保护的内容
作者:方泰攻略站时间:2025-04-06 14:59:46
本站 4 月 6 日消息,一项新研究似乎为 OpenAI 至少使用部分受版权保护内容来训练其人工智能模型的指控提供了依据。

本站注意到,OpenAI 正面临由作家、程序员以及其他版权持有者提起的诉讼,这些原告指责该公司在未经许可的情况下,使用他们的作品 —— 包括书籍、代码库等,来开发其模型。尽管 OpenAI 一直声称其享有合理使用的抗辩理由,但原告方则认为美国版权法中并无针对训练数据的豁免条款。
该研究由华盛顿大学、哥本哈根大学和斯坦福大学的研究人员共同撰写,提出了一种新方法,用于识别像 OpenAI 这样通过应用程序接口(API)提供服务的模型所“记忆”的训练数据。
AI 模型本质上是预测引擎,通过大量数据训练,它们能够学习各种模式,从而生成文章、照片等。虽然大多数输出并非训练数据的逐字复制,但由于模型的“学习”方式,部分内容不可避免地会被模型记忆下来。此前已有研究发现,图像模型会重复生成其训练数据中电影的截图,而语言模型则被观察到存在剽窃新闻文章的行为。
该研究的核心方法依赖于研究人员提出的“高意外性”词汇,即在大量作品中显得不常见的词汇。例如,在句子“Jack and I sat perfectly still with the radar humming”中,“radar”(雷达)一词被认为是高意外性的,因为从统计学角度来看,它出现在“humming”(嗡嗡作响)之前的可能性比“engine”(引擎)或“radio”(收音机)等词要低。
共同作者对包括 GPT-4 和 GPT-3.5 在内的几种 OpenAI 模型进行了测试,通过从虚构小说片段和《纽约时报》文章中移除高意外性词汇,然后让模型尝试“猜测”被屏蔽的词汇,来寻找记忆迹象。研究人员认为,如果模型能够成功猜出这些词语,则很可能表明该模型在训练过程中记忆了这些片段。
根据测试结果,GPT-4 显示出记住了流行小说书籍的部分内容,包括一个包含受版权保护电子书样本的数据集 BookMIA 中的书籍。结果还表明,该模型记住了《纽约时报》文章的部分内容,尽管比例相对较低。
华盛顿大学的博士生、该研究的共同作者阿比拉沙・拉维奇汉德(Abhilasha Ravichander)对 TechCrunch 表示,这些发现揭示了模型可能接受训练的“有争议的数据”。
长期以来,OpenAI 一直倡导放宽对使用受版权保护数据开发模型的限制。尽管该公司已经达成了一些内容许可协议,并提供了允许版权所有者标记不希望其用于训练的内容的退出机制,但该公司一直在游说多个**将围绕人工智能训练方法的“合理使用”规则编入法典。
相关文章
-
 WinRAR 旧版本存安全漏洞,可绕过 Windows 安全警告执行恶意软件
WinRAR 旧版本存安全漏洞,可绕过 Windows 安全警告执行恶意软件本站 4 月 7 日消息,WinRAR 作为电脑用户中广受欢迎的压缩软件,数十年来一直为用户提供便捷的数据压缩服务,方便用户将文件压缩成更小的体积以便于传输。然而,除最新版外的所有 WinRAR 版本
-
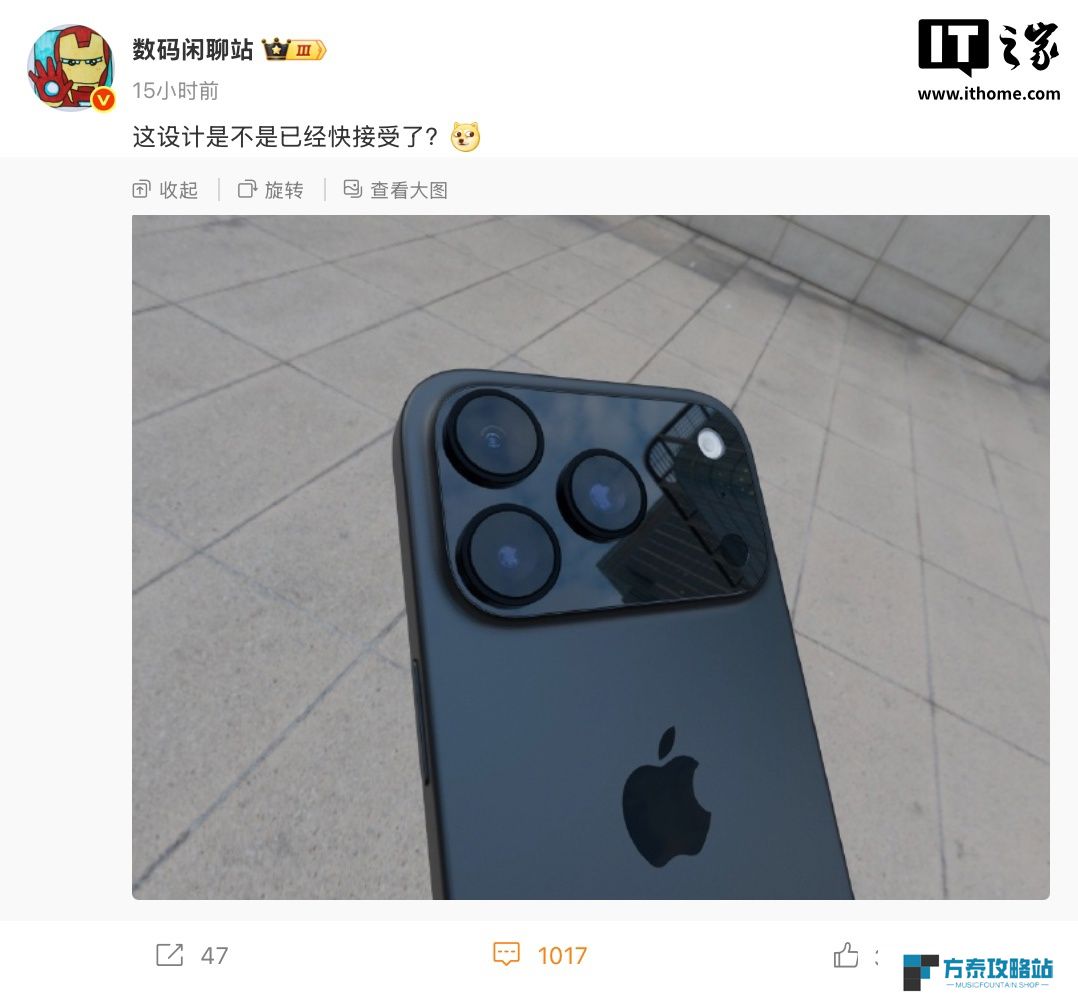 苹果 iPhone 17 Pro 系列新机模渲染曝光,直观展示后置“横向大矩阵”摄像头模组设计
苹果 iPhone 17 Pro 系列新机模渲染曝光,直观展示后置“横向大矩阵”摄像头模组设计本站 4 月 7 日消息,博主@数码闲聊站 发布一张机模渲染图,展示了苹果即将推出的iPhone 17 Pro系列手机设计,直观展示了该机“横向大矩阵”摄像头模组,考虑到该博主发布内容有较高准确度,该
-
 科学家利用细菌修复月球砖块裂缝,助力月球基地建设
科学家利用细菌修复月球砖块裂缝,助力月球基地建设本站 4 月 7 日消息,建设月球基地一直是人类太空探索的重要目标之一,而如何利用月球本地资源降低成本是关键问题。近期,印度科学研究所(IISc)的一项新研究为月球基地建设带来了新的希望,该研究基于月
-
 古尔曼称苹果公司不会在美国组装 iPhone:成本太高
古尔曼称苹果公司不会在美国组装 iPhone:成本太高本站 4 月 7 日消息,彭博社的马克・古尔曼发文,认为在美国当局最新关税政策下,苹果公司仍然不会在这几年内将iPhone手机生产转移到美国本土,这主要是因为成本太高。古尔曼认为,苹果公司会与其供应链
-
 全国首个,深圳海关智能查验机器人引入“满血版”DeepSeek-R1
全国首个,深圳海关智能查验机器人引入“满血版”DeepSeek-R1本站 4 月 7 日消息,据科技日报本月消息,深圳海关自主研发的智能查验机器人已引入海关系统全国首个“满血版”DeepSeek-R1,实现技术升级,并在进口危化品监管和水果通关领域形成示范。据介绍,在
-
 2025 清明档新片票房破 3 亿,《我的世界大电影》《向阳・花》《不说话的爱》位列前三
2025 清明档新片票房破 3 亿,《我的世界大电影》《向阳・花》《不说话的爱》位列前三感谢本站网友 雨雪载途 的线索投递! 本站 4 月 6 日消息,据猫眼专业版数据,2025 年 4 月 6 日 17 时 20 分,2025 年清明档新片





