中科大华为发布生成式推荐大模型:昇腾 NPU 可部署,背后认知一同公开
作者:方泰攻略站时间:2025-04-07 10:04:42
推荐大模型也可生成式,并且首次在国产昇腾 NPU 上成功部署!
在信息爆炸时代,推荐系统已成为生活中不可或缺的一部分。Meta 率先提出了生成式推荐范式 HSTU,将推荐参数扩展至万亿级别,取得显著成果。
近期,中科大与华为合作开发了推荐大模型部署方案,可应用于多个场景。探索过程中还有哪些经验与发现?最新公开分享来了。
报告亮点包括:
总结推荐范式发展历程,指出具备扩展定律的生成式推荐范式是未来趋势;
复现并研究不同架构的生成式推荐模型及其扩展定律;通过消融实验和参数分析,解析 HSTU 的扩展定律来源,并赋予 SASRec 以可扩展性;
验证 HSTU 在复杂场景和排序任务中的表现及扩展性;
团队展望并总结未来研究方向。
具备扩展定律的生成式推荐范式正在成为未来趋势
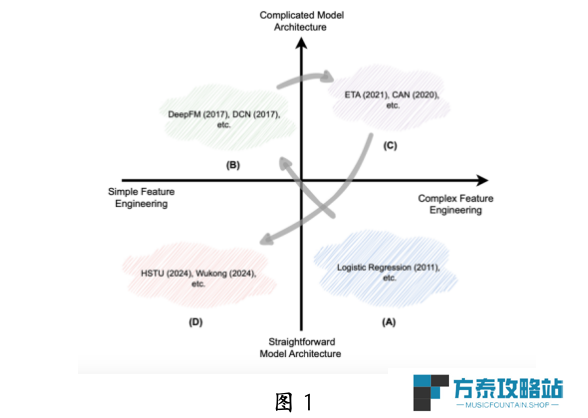
如图 1 所示,推荐系统的发展趋势是逐渐减少对手工设计特征工程和模型结构的依赖。在深度学习兴起之前,受限于计算资源,人们倾向于使用手工设计的特征和简单模型(图 1A)。
随着深度学习的发展,研究者专注于复杂模型的设计,以更好地拟合用户偏好,并提升对 GPU 并行计算的利用率(图 1B)。
然而,随着深度学习能力的瓶颈,特征工程再次受到关注(图 1C)。
如今,大语言模型扩展定律的成功启发了推荐领域的研究者。扩展定律描述了模型性能与关键指标(如参数规模、数据集规模和训练资源)之间的幂律关系。通过增加模型深度和宽度,并结合大量数据,可以提升推荐效果(图 1D),这种方法被称为推荐大模型。
近期,HSTU 等生成式推荐框架在此方向取得了显著成果,验证了推荐领域的扩展定律,引发了生成式推荐大模型研究的热潮。团队认为,生成式推荐大模型正在成为颠覆当前推荐系统的下一个新范式。
在此背景下,探索哪些模型真正具备可扩展性,理解其成功应用扩展定律的原因,以及如何利用这些规律提升推荐效果,已成为当前推荐系统领域的热门课题。
基于不同架构的生成式推荐大模型扩展性分析
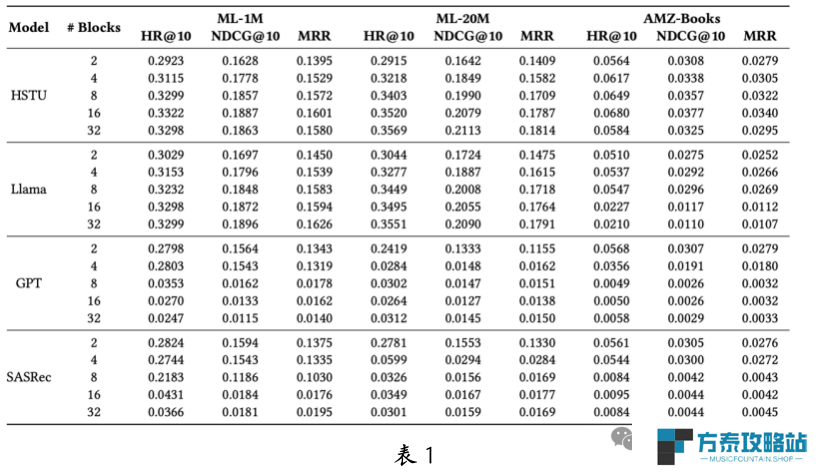
为了评估生成式推荐大模型在不同架构下的扩展性,团队对比了 HSTU、Llama、GPT 和 SASRec 四种基于 Transformer 的架构。
在三个公开数据集上,通过不同注意力模块数量下的性能表现进行分析(见表 1)。结果显示,当模型参数较小时,各架构表现相似,且最优架构因数据集而异。
然而,随着参数扩展,HSTU 和 Llama 的性能显著提升,而 GPT 和 SASRec 的扩展性不足。尽管 GPT 在其他领域表现良好,但在推荐任务上未达预期。团队认为,这是因为 GPT 和 SASRec 的架构缺乏专为推荐任务设计的关键组件,无法有效利用扩展定律。
生成式推荐模型的可扩展性来源分析
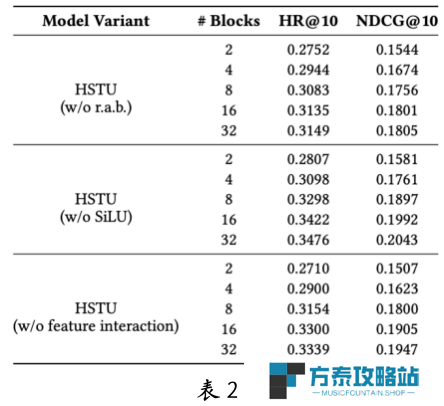
为了探究 HSTU 等生成式推荐模型的可扩展性来源,团队进行了消融实验,分别去除了 HSTU 中的关键组件:相对注意力偏移(RAB)、SiLU 激活函数,以及特征交叉机制。
实验结果(见表 2)显示,单一模块的缺失并未显著影响模型的扩展性,但 RAB 的移除导致性能明显下降,表明其关键作用。
为了进一步分析赋予模型扩展定律的因素,团队比较了 SASRec 与扩展性良好的 HSTU 和 Llama 的区别,发现主要差异在于 RAB 和注意力模块内的残差连接方式。
为验证这些差异是否为扩展性的关键,团队为 SASRec 引入了 HSTU 的 RAB,并调整其注意力模块的实现方式。
实验结果(见表 3)显示,单独添加 RAB 或修改残差连接并未显著改善 SASRec 的扩展性。然而,当同时修改两个组件后,SASRec 展现出良好的扩展性。这表明,残差连接模式与 RAB 的结合,为传统推荐模型赋予了扩展性,为未来推荐系统的扩展性探索提供了重要启示。

生成式推荐模型在复杂场景和排序任务中的表现
复杂场景中的表现
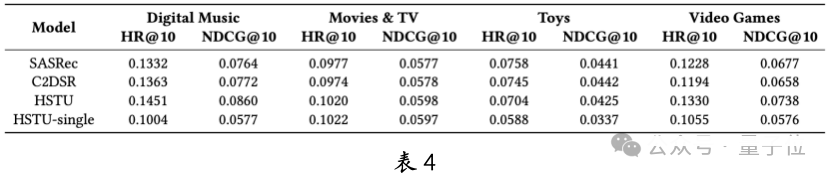
HSTU 在多域、多行为和辅助信息等复杂场景中表现出色。以多域为例,HSTU 在 AMZ-MD 的四个域中始终优于基线模型 SASRec 和 C2DSR(见表 4)。
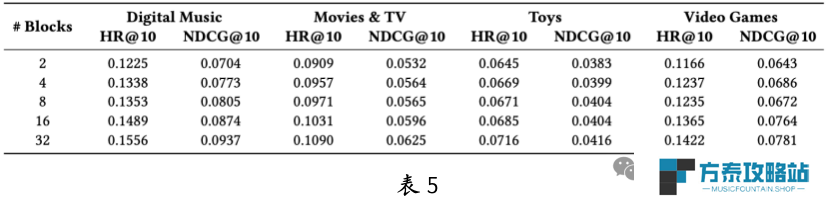
与单域独立训练的 HSTU-single 相比,多域联合训练的 HSTU 表现更佳,证明了多域联合建模的优势。表 5 显示,HSTU 在多域行为数据上的扩展性显著,尤其在规模较小的场景如 Digital Music 和 Video Games 上。这表明 HSTU 在解决冷启动问题上具有潜力。
在排序任务中的表现
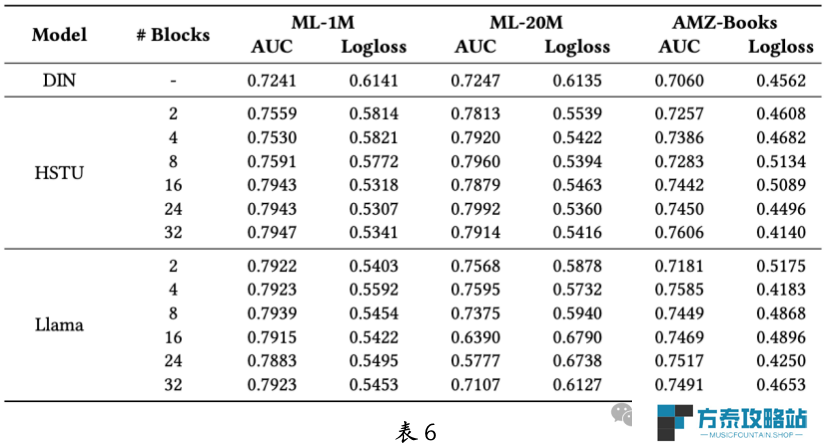
排序是推荐系统中重要的一环,团队深入探讨了生成式推荐模型在排序任务中的有效性和扩展性。正如表 6 所示,生成式推荐大模型在性能上显著优于 DIN 等传统推荐模型。尽管在小规模模型下,Llama 的表现优于 HSTU,但 HSTU 在扩展性方面更具优势,而 Llama 在扩展性上显得不足。
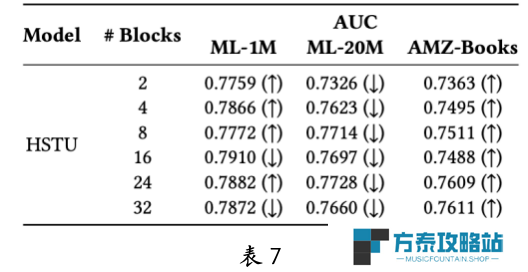
团队还研究了负采样率和评分网络架构对排序任务的影响,并进行了全面分析。此外,还探讨了缩减 embedding 维度对性能的影响。缩小 embedding 维度(表 7)提升了小数据集 ML-1M 和 AMZ-Books 的性能,但在大数据集 ML-20M 上则有所下降。这表明,推荐大模型的扩展定律不仅受垂直扩展(注意力模块数量)影响,也受水平规模(embedding 维度)影响。
未来方向和总结
在技术报告中,团队指出了数据工程、Tokenizer、训练推理效率等推荐大模型未来研究的潜力方向,这些方向将帮助解决当前的挑战并拓宽应用场景。
论文链接:https://arxiv.org/abs/2412.00714
主页链接:https://github.com/USTC-StarTeam/Awesome-Large-Recommendation-Models
本文来自微信公众号:量子位(ID:QbitAI),作者:认知智能全国重点实验室 & 华为诺亚方舟,原标题《中科大华为发布生成式推荐大模型,昇腾 NPU 可部署,背后认知一同公开》
相关文章
-
 刺香出装教程攻略大全(让你在游戏中成为无敌的存在!)
刺香出装教程攻略大全(让你在游戏中成为无敌的存在!)刺香是一款热门的手机游戏,其中的出装是玩家们提升自己战斗力的重要手段。本篇文章将为大家提供详细的刺香出装教程攻略大全,帮助玩家们在游戏中成为无敌的存在!一、突破极限之路——出装基础通过了解角色属性和技
-
 WinRAR 旧版本存安全漏洞,可绕过 Windows 安全警告执行恶意软件
WinRAR 旧版本存安全漏洞,可绕过 Windows 安全警告执行恶意软件本站 4 月 7 日消息,WinRAR 作为电脑用户中广受欢迎的压缩软件,数十年来一直为用户提供便捷的数据压缩服务,方便用户将文件压缩成更小的体积以便于传输。然而,除最新版外的所有 WinRAR 版本
-
 1.神秘护甲:提升无极抗性,成为不可撼动的战士之神
1.神秘护甲:提升无极抗性,成为不可撼动的战士之神无极作为一款热门游戏中的强力英雄,拥有出色的技能和属性,成为许多玩家心目中的霸主。本文将为大家带来最新的无极出装铭文攻略,助您在游戏中取得更好的战绩!1 神秘护甲:提升无极抗性,成为不可撼动的战士之神
-
 Meta 新旗舰 AI 模型 Llama 4 Maverick 测试成绩遭质疑,被指针对性优化
Meta 新旗舰 AI 模型 Llama 4 Maverick 测试成绩遭质疑,被指针对性优化本站 4 月 7 日消息,Meta 公司上周发布了一款名为 Maverick 的新旗舰 AI 模型,并在 LM Arena 测试中取得了第二名的成绩。然而,这一成绩的含金量却引发了诸多质疑。据多位 A
-
 李白在幻想领域的技能搭配攻略(掌握李白技能搭配,成就无敌之主)
李白在幻想领域的技能搭配攻略(掌握李白技能搭配,成就无敌之主)在幻想领域这款游戏中,李白是一位非常强力的角色,他拥有多种技能可以让他在战斗中展现出无与伦比的强大力量。本文将为大家介绍李白在幻想领域的技能搭配攻略,帮助玩家更好地掌握李白,成为无敌之主。一:技能搭配
-
 英伟达工程师修改 Linux 内核致 AMD GPU 性能下降,后又将其修复
英伟达工程师修改 Linux 内核致 AMD GPU 性能下降,后又将其修复本站 4 月 7 日消息,一名英伟达工程师近日在 Linux 内核中提交了一个修复补丁,解决了 AMD 集成和独立 GPU 硬件上出现的性能倒退问题。然而令人意外的是,这位工程师正是最初引入这一问题的





